
Algorithms provide businesses with more efficient ways to manage their data; however, they are not without problems. On the bright side, algorithms provide certain predictability to business models. They can be relied on for precise decisions and information on what will drive the key metrics. On the darker side, algorithms can increase business risks. Can the risk presented by an algorithm outweigh its benefits? What are some ways to improve the accuracy of algorithms?
One way to explain this is to understand that algorithms are prone to bias, which can lead to mistakes. Algorithms are programs that solve a problem through a set of instructions rather than through human thought. They are often used in machine learning and artificial intelligence to perform tasks that humans previously did. There could be many reasons machine learning could fail a business, such as inadequate data, improper use of algorithms, and error in human judgment. When a model is trained, both data and algorithms play a significant role. However, humans develop those algorithms, and executives in the company sponsor them. So, ultimately, humans are responsible for their actions. So, how did a real estate company lose $300+ Million flipping houses? Let’s look at Zillow’s iBuying Algorithm.
Zillow’s iBuying Algorithm
Zillow Group is a leading provider of real estate data and analytics and the most popular home-buying and selling platform in the United States. Zillow, which rose to success with online listings, had bet its future on Zillow Offers. The idea is that this algorithm-based home-flipping outfit would buy houses and make minor renovations before quickly selling them for profit (Gandel, 2021). Let me explain this in a bit more detail.
One of the most challenging aspects of buying a new property is coordinating the move-out and move-in dates. If you’re looking for a property and want to leave your old one as soon as possible, this could mean a gap in your dates, requiring a temporary stay. Multiple venture capital-funded tech startups have appeared recently to solve this pain point. Some companies include Opendoor and Offerpad (Parker, 2021). Also, Zillow Offers started operating in the same business. These AI-mediated marketplaces are aptly called “iBuyers”. The algorithmically determined “fair market price” makes buying and selling much easier, and you can take the money upfront and find a new home on your own time. You could also take your time to search and let the transaction close at your own pace.
If you have ever been looking to buy a house, you may have encountered bidding wars. Some companies such as Collateral Analytics, CoreLogic, and Quantarium offer home value analytics to estimate the price of the house. Since these tools show the estimated house price, buyers have different financial capabilities and risks. Individuals who are buying at a higher price to flip houses are managing the risk of the investment themselves at a tiny scale.
However, things can be different if an algorithm makes the pricing decisions (i.e., automated home valuations) on a large scale. One could argue that in a rising market, it is difficult to lose money, but if an algorithm or management is aggressive or if KPIs are different (e.g., gaining market share is a goal) then there could be unexpected consequences. Two things can happen, the seller will ask for more, and the buyer may eventually pay more. For iBuyers, they have their algorithms to estimate the house price, and if they use similar features, they will buy the house at a higher price. Zillow paid higher prices, as shown below in Figure 1(Parker, 2021). The price differential between Zillow and its competitors is high for the average purchase price.
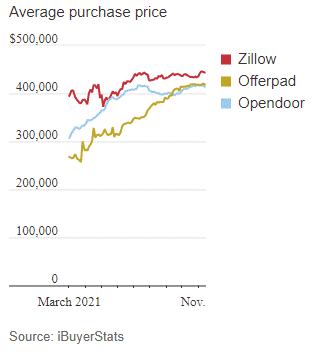
From the industry perspective, the iBuyer market trends show that market share and volume of purchases have almost doubled, but the median markup has dropped by about 70%. The iBuyer median price also saw a jump of 13%. In summary, Charts in Figure 2 (Zillow, 2021b) show that the iBuyer algorithms gained market share while increasing the median purchase price; further, the median markup for iBuyer sales declined, and inventory of iBuyer houses rose as iBuyer re-sales did match up with iBuyer purchases. As in so many game-changing examples of modern technology, Zillow’s downfall wasn’t caused by the tool itself but by how it was used.

Example: Suppose a house is $280,000, and an algorithm incorrectly predicts that a home is worth $20,000 more. This error led to a bidding war for the house and the eventual sale for $300,000 more than its asking price. While the homeowner benefits from bidding wars, the buyer usually pays the price. Therefore, if an algorithm flips houses, it can also lose money. Without going into the operational and strategic aspects of the business, a real estate algorithm can play a role in house-buying and selling by predicting house prices. Zillow took a significant risk on its prediction algorithm.
In 2021, Zillow CEO David Barton voiced concerns about the company’s AI-based home buying algorithm on CNBC and the Q3 conference call with investors. The company still used its Algorithm to buy 9,680 homes in the third quarter. According to Q3 earnings transcript, Zillow Group co-founder and CEO Rich Barton said, “We’ve determined the unpredictability in forecasting home prices far exceeds what we anticipated and continuing to scale Zillow Offers would result in too much earnings and balance-sheet volatility.”
In the 3rd quarter, the losses for the company included an inventory write-down of $304 million within the homes segment. The company expected losses of between $240 million to $265 million in Q4, primarily due to homes it is anticipating purchasing that quarter (Zillow, 2021a). Therefore, one of the key takeaways after Zillow Group’s unexpected decision to shutter its home buying business is that it will result in 2,000 employees losing their jobs, a $304 million write-down for Q3 expenses. The stock price has since dropped accordingly. The company’s market cap, which closed at the peak of $48.35 billion in February 2021, is now (August 2022) around $8 billion.
Due to a prediction algorithm, Zillow and its shareholders lost money. Also, Zillow employees lost their jobs. In December 2021, Zillow announced that it has made good progress in winding down its Zillow Offers inventory and has sold, is under contract to sell, or has reached an agreement on disposition terms for more than half of the homes it expected to resell. Further, Zillow Group’s Board of Directors authorized the repurchase of up to $750 million of its Class A common stock, Class C capital stock, or a combination of both (Zillow, 2021a).
This type of reliance on algorithms could be an omen for other industries that extensively use algorithms. For the real estate algorithm, the real question is if there is something that could have been done to avoid this situation.
Let’s look at the role of data in machine learning systems and some ways to improve the accuracy of an algorithm.
The Role of Data in Machine Learning Systems
Machine learning systems are designed to make predictions based on data input. The more data input the system has, the better it can make predictions. However, there is a risk of overfitting when a machine learning system is trained with too much data. The accuracy of an algorithm may seem high on the training data but poor on the testing data. Also, many algorithms (e.g., Random Forest, Linear Regression, etc.) do not generalize well if they are used to predict (for example, rising real estate prices) previously unseen training data. This means it could not extrapolate from what is learned and apply it to new input.
In Zillow’s case, there is no public information on how the Algorithm worked and what machine learning models were used to make the predictions. Therefore, I can only explain how this could happen in machine learning and what could be done to improve modeling accuracy. For example, the model in production may have had a higher accuracy due to overfitting, but the model did not perform well on the test data. Check the bias-variance trade-off in Figure 3 below.

As we can see above, there is a “sweet spot” between an under-fitting and over-fitting model. Also, k-folds cross-validation can assess the accuracy of the model. Linear models are great for avoiding overfitting, but they don’t work for all real-world problems. It’s crucial to avoid overfitting if the underlying problem is nonlinear. Below are a few techniques to prevent overfitting (IBM, 2021):
Early stopping: This approach is a trade-off between exploring the noise within the model and underfitting training data. There is an optimal point where data exploration and overfitting meet, but it’s hard to find by trial and error; hence early stopping could work before the model learns from noise. We know that too much noise can cause an algorithm to underfit.
Train with more data: Expanding the training set to include more data can go a long way toward making accurate predictions. This is because the model has more chances to determine which relationships dominate between input and output variables. However, this only works well when the data is clean and complete. Otherwise, it could just be adding more complexity to the model.
Data augmentation: You can improve the stability of your prediction by using noisy input data, but only very sparingly. It’s better to add clean, relevant data.
Feature selection: When building a prediction model, you need to define the parameters or features that drive it. Especially when there are many redundant or irrelevant features present, feature selection is what you need to do to identify your data’s most important or more worthwhile characteristics. You cut out any redundant or irrelevant ones that you don’t need. This is not dimensionality reduction, but it is an important process. Both dimensionality reduction and feature selection can help in simplifying the model.
Regularization: If you’re unsure what features to remove from your model, regularization can be particularly helpful. It applies a ‘penalty’ to the input parameters with the larger coefficients, which limits the amount of variance in your model. There are a number of different regularization methods, such as L1 regularization or Lasso regularization. They all seek to identify and reduce noise within the data.
Ensemble methods: Ensemble learning methods group together a set of classifiers, e.g., decision trees, and aggregate their predictions to identify the most likely outcome. The most well-known forms are ‘bagging’ and ‘boosting.’
Conclusion
Machine learning techniques can be used in any business process to automate it, but this may not always be the best approach. Since algorithms at scale can pose many business risks, data scientists and executives must evaluate the impact of algorithms and take steps to mitigate the risks. Data scientists must ensure that they use appropriate techniques to improve prediction accuracy. Business executives must evaluate unique elements of a business for data-driven decision-making. The case of a real estate algorithm to flip houses with unintended consequences should be taken as a warning for other companies using algorithms in their operations.
Source:
Gandel, S. (2021). Zillow, facing big losses, quits flipping houses and will lay off a quarter of its staff. Retrieved from https://www.nytimes.com/2021/11/02/business/zillow-q3-earnings-home-flipping-ibuying.html
IBM. (2021). Overfitting. Retrieved from https://www.ibm.com/cloud/learn/overfitting
Parker, W. P., Konrad. (2021). What Went Wrong With Zillow? A Real-Estate Algorithm Derailed Its Big Bet. Retrieved from https://www.wsj.com/articles/zillow-offers-real-estate-algorithm-homes-ibuyer-11637159261
Zillow. (2021a). Zillow Group Reports Third-Quarter 2021 Financial Results & Shares Plan to Wind Down Zillow Offers Operations [Press release]. Retrieved from https://investors.zillowgroup.com/investors/news-and-events/news/news-details/2021/Zillow-Group-Reports-Third-Quarter-2021-Financial-Results–Shares-Plan-to-Wind-Down-Zillow-Offers-Operations/default.aspx
Zillow. (2021b). Zillow Q3 2021 iBuyer Report. Retrieved from https://www.zillow.com/research/zillow-ibuyer-report-q3-2021-30386/